



There are many complicated aspects of technical SEO that not every business owner needs to know about.
The robots.txt file is one that they should.
It’s essentially a roadmap for your website that tells Google what should be read and what should be ignored.
This article will share everything you need to know about this file.
Best of all, it’s not difficult and can be accessed easily with just a few clicks (no need to log in to your host).
Let’s get started.
What is a Robots.txt File (is it complicated)?
A robots.txt file is a file added to the root of your website that gives directions to Google and other search engine crawlers.
It was created from a protocol in the early ‘90s to help give rules to the wild west of the internet.
It gives webmasters complete control of what can and cannot be crawled by search engines.
Why Did Robots.txt Come About?
Let’s think about the results on a search engine results page.
You’re not seeing a collection of every website on the internet ranked due to some unknown ranking factor (over 200 of them).
Instead, it shows Google’s understanding of all of those websites. It’s an index of what Google’s spiders are able to crawl on the internet and how Google sees these pages’ importance.
The robots.txt allows webmasters to say to Google, “show these pages, but don’t show these.”
Some websites have thousands and thousands of pages, and it’s important to prioritize your crawl budget. For example, this is useful for ecommerce websites, which sell many products.
You can tell Google that your redundant database files are not worth adding to their index.
What Might I Limit Access to on My Website?
As a small business owner, it might seem like you want Google to see every part of your website.
However, it doesn’t make sense to show certain pages.
For example, whenever someone visits your website and fills out a contact form, they should be taken to a thank you page.
(You are doing this on your site, right?)
Thank you pages are the best way to track conversions and ask for follow-up information right after a user has converted.
These thank you pages are important for tracking what’s working well. If you don’t tell Google not to crawl thank you pages on your site, then anyone can access them.
You may even end up with thank you pages showing up in organic search results, which you don’t want.
People may click through to the page and you’ll end up with skewed metrics. The users won’t get as much value, either, because they don’t enter your CRM (we prefer Hubspot) unless they fill out the form.
Other pages that make sense to block in the robots.txt are test pages.
Whenever we create new pages, we create a test version of them on a /test URL.
Our robots.txt blocks all /test URLs. This is helpful in case we forget to block individual pages via noindexing them.
Finally, it makes sense to block backend pages.
In the past, I’ve seen WordPress files show up accidentally in search results for websites. Adding a disallow for /wp-admin or /admin is a great way to prevent Google from looking at the backend of your website.
How Do I Edit the Robots.txt File of My Site?
To edit the file, you could view and edit the robots.txt of your site at the host level, but that can be complicated if you don’t understand hosting.
If you have a WordPress website, you can add the Yoast SEO plugin to gain access instantly.
Navigate to Yoast SEO → Tools → File editor
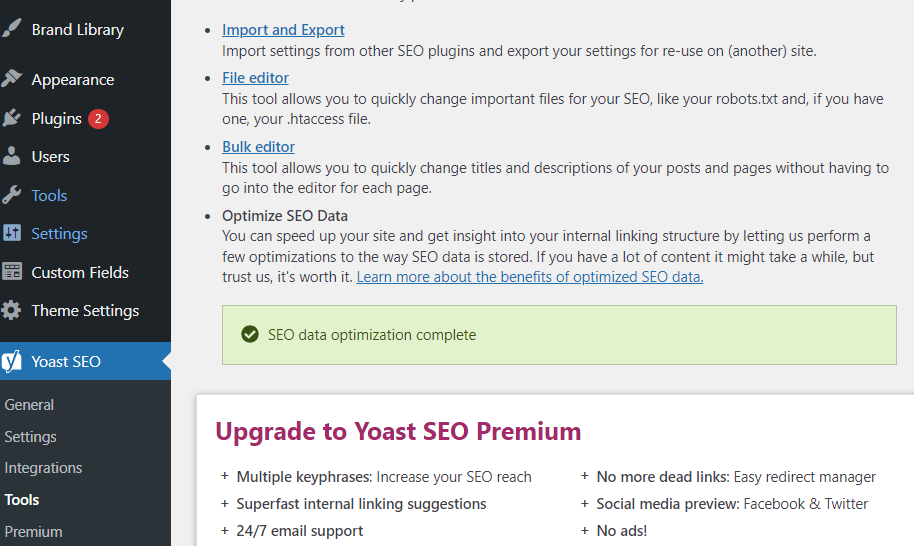
From here, you can edit your robots.txt and your .htaccess files.
The .htaccess file is a file that is used for website configuration such as redirecting URLs which can be used to tell the server what to do when they come to your website.
It brings up a WYSIWYG where you can type right in the browser and click the save button.
What is Involved in a Robots.txt File?
Editing a Robots.txt file may seem like editing a ton of code.
In reality, it’s written in plain English with the exception of the # symbol.
There are a few main areas to show in a robots.txt file. I’ve summarized the four main ones you need to know below:
- user-agent: this shows the name of the crawler like google bot or msnbot
- disallow: prevents crawling of certain files, directories, or web pages
- sitemap (optional): shows the location of the sitemap
- *: This is a RegEx symbol that means any number of character
- #: This is a RegEx symbol that means ignore this line
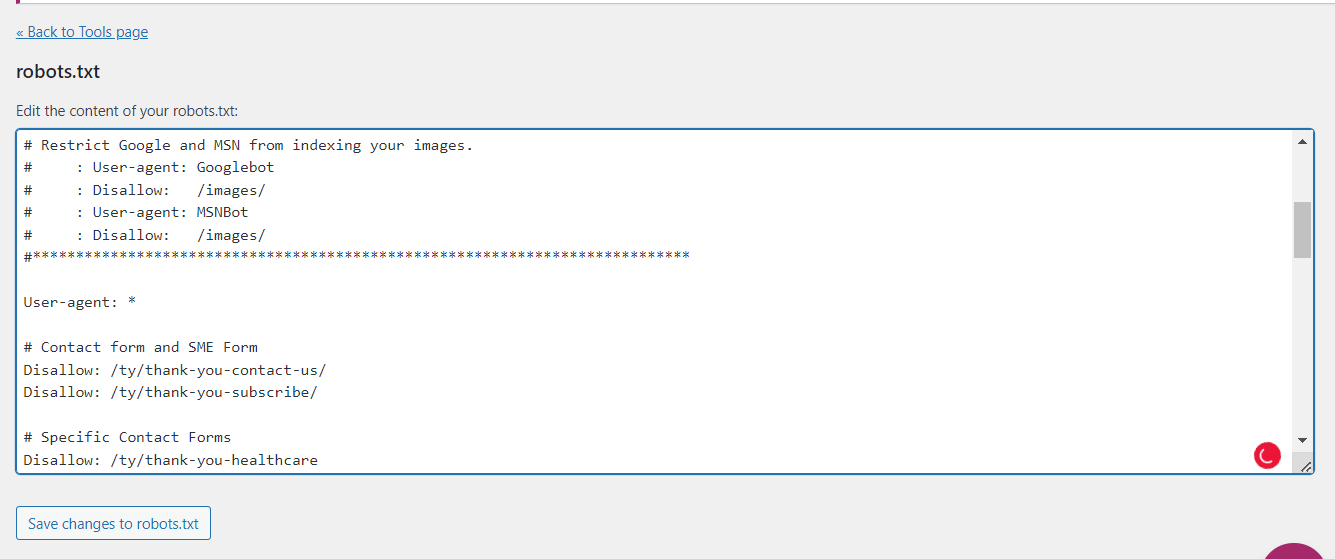
Let’s see these in action in the milesit.com robots.txt file.
Breaking Down Our Robots.txt File
The robots.txt is a public-facing file. Therefore, there isn’t any proprietary information included.
I can just as easily go to Amazon.com’s robots.txt file right now.
In fact, I did.
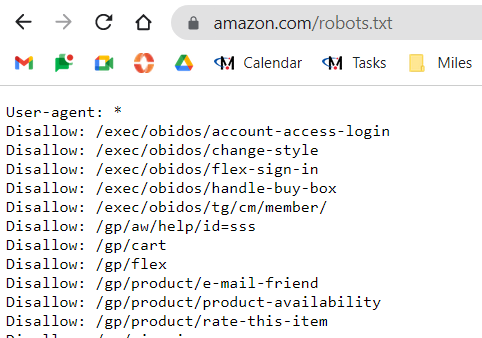
It doesn’t tell me anything or allow me to hack into their servers in any way.
That being said, let’s break down the elements from the Miles IT robots.txt file.
The Preamble

First, we have the instructions. The # symbol at the beginning means “ignore this line”
Think of this section as comments in HTML. Sometimes, developers leave instructions for other developers, and different coding systems have their own ways of doing this.
For HTML, you would use: <!–
You can certainly omit this section, but it can be helpful for newer site owners to leave it in.
User Agent
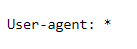
Using our understanding of RegEx (which isn’t much), we know that * means anything.
Therefore, we’re giving directions for our website so that any search engine can follow all of the rules we lay out in the following lines.
If we wanted to, we could say user-agent: Googlebot and have specific instructions.
Disallowed Pages Broken Down by Group
I like to think of my robots.txt file as a roadmap more than anything. Anyone in our marketing division can see the initiatives I’m working on or key URLs from this file.

Using the # symbol, I’m able to group disallows together, making them easier to add to or modify later.
I break down our contact form and main subject matter form separately from more specific contact forms.
Also, we’ve discussed disallowing pages or folders. I like to use the robots.txt to list out specific pages to ensure I don’t forget their URLs.
These pages aren’t necessarily orphan pages, but they’re not always as easy to find.
Knowing which opt-ins I have running, along with a quick link to them, is handy for me and anyone on my marketing team who needs a specific URL.
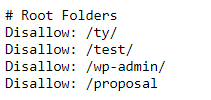
Next, I have Root folders, which are the main subdirectories that I want to block.
Thank you pages, test pages, and the backend of WordPress can all be blocked here.
Putting just /ty/ means to block /ty (thank you) as well as any page that has /ty/ at the beginning of it.
Root Folders
Sitemap
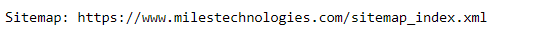
Finally, I have the Miles IT sitemap.
For a long time, I would forget the URL of this page, so I stuck it in the robots.txt file.
Then, I read that others were doing the same.
It makes sense that search engines are using this as their own directory and roadmap of instructions; why not include a link to every page you want them to see (your XML sitemap)?
It may not help the bot understand your website, but it certainly doesn’t hurt and makes the URL easier to find.
Can I Break Anything in This File?
Unlike the .htaccess file, you shouldn’t easily break anything in the robots.txt file.
Forgetting to add a # before commented-out files is the biggest threat to this file.
The error you do want to avoid is having disallow: / in your robots.txt file.
This tells Google NOT TO CRAWL YOUR WEBSITE – effectively making your site invisible.
The only scenario where you’d need this is if your website is under construction or being created. You don’t want to allow Google to see content before it’s ready.
Otherwise, Google may associate your business with lorem ipsem (filler content) rather than your business industry, which could be problematic.
Conclusion
And there you have it: a super technical-sounding term broken down for anyone to understand.
There is a lot of power in the robots.txt file, and you have complete ownership of it.
Make sure that your webmaster (especially if that’s you) knows about this file and is well-equipped to incorporate it into your marketing strategy.
